如今,数字化潮流席卷而来,联邦学习因其特性——无需共享数据集即可共同训练模型——而备受瞩目。但问题是,如何保障其隐私安全并提升系统的稳固性,这成了众人热议的焦点。

联邦学习基本机制
联邦学习的一大特点是,参与方可以在不共享数据的前提下,共同对包含全面数据的模型进行训练。就像不同地区的科研团队,各自拥有自己的数据集。他们不需要合并数据,就能通过联邦学习的方法进行模型训练。在实际应用中,众多公司或机构各自保存着独立的数据,联邦学习提供了一种合作途径来训练机器学习模型,显著降低了数据整合的工作量和资源消耗。
联邦学习领域,隐私安全至关重要,尤其是当数据中涉及个人隐私或商业机密等敏感内容时。各方会在各自地方处理数据,只将模型更新上传到服务器。这种方式降低了数据直接交换的风险,有效保障了医疗、金融等行业在联邦学习应用中的数据隐私。
差分隐私概念
在本地化差分隐私领域,我们主要研究的是ε-本地化差分隐私。这里,有n个用户,每个人各自保存一条信息。当算法M在对比两条信息t和t’时,会给出满足特定不等式的答案。每个用户都会执行随机扰动算法M,并将所得结果传送给服务器。通过设定隐私预算,我们能够保障个人信息的安全。比如,在一个用户群体中,每个人的敏感信息在经过这种处理后再上传,这样就能有效维护用户的隐私。

对于任意邻近的数据集D与D',以及随机算法M及其任意输出S,都存在一个不等式。只要满足这一不等式,算法M便能够实现隐私保护。这保证了聚合函数的输出结果无法识别出特定参与者是否参与了训练。尽管这种保护受到隐私预算的限制。在现实世界的众多数据分析场景中,尤其是在处理敏感用户信息时,这一特性显得尤为重要。
抵御后门攻击
在联邦学习训练过程中,存在后门攻击的可能性。攻击者可能会尝试在某个训练阶段向服务器发送特定的模型更新。Median聚合规则起到了保护作用,主要设备会对多个计算节点的参数进行排序,然后选取中位数作为整体的模型参数。

Krum的方案至关重要。即便选中的节点设备受到攻击或怀有恶意,它们提供的参数所引发的恶意影响也相对较小,因为它们的参数与普通计算节点设备的参数相似。另外,一旦服务器接收到的攻击者模型更新超过阈值T,就可以直接忽略该参与者,这样可以有效减少后门攻击的风险。
成员推断攻击与防御
在成员推断攻击中,攻击者试图查明参与方是否用特定数据训练了模型,或者这些数据是否属于某个特定参与者。这种攻击对数据隐私有很大危害。但现有研究表明,差分隐私技术能在一定程度上提供防护。尽管如此,它也遇到了不少难题。针对不同类型的攻击,需要采取不同的差分隐私策略,其防护效果也不尽相同。
不同差分隐私技术比较
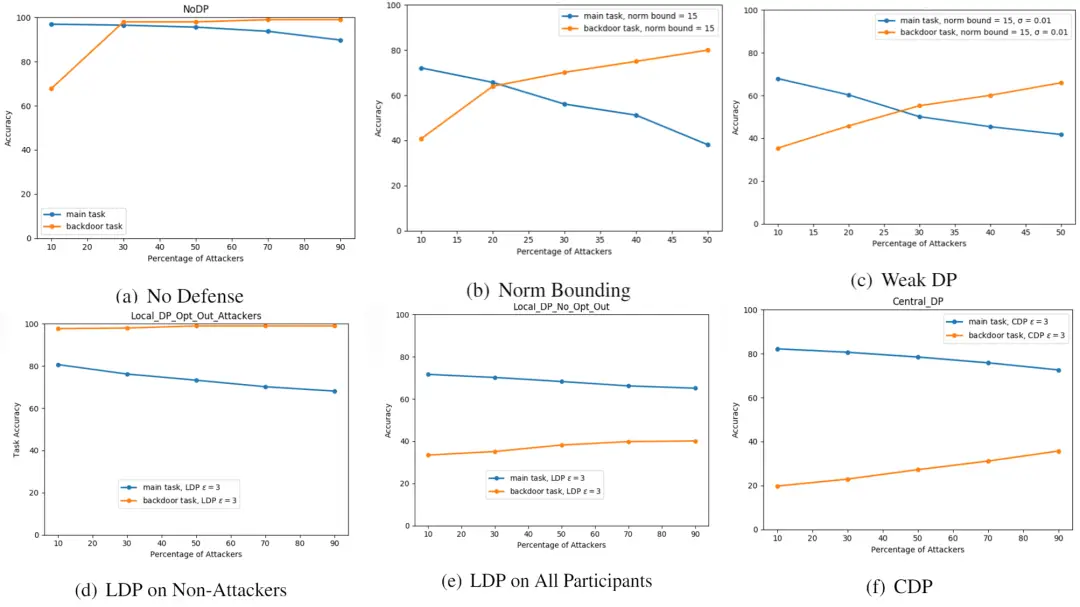
研究显示,在降低后门攻击成功率方面,LDP与CDP相较于Norm Bounding和Weak DP更具优势。不过,两者的效果存在差异。以处理大规模数据集的联邦学习任务为例,这种差异表现得尤为明显。
CDP在防范成员推断攻击上比LDP更有优势。不过,在处理属性推理攻击时,很难找到一个既能确保效用水平又能有效防御的实验方案。这表明,尽管差分隐私技术在保障隐私和提升系统鲁棒性上已有一定成果,但面对不同攻击类型,不同差分隐私技术的表现各有不同,我们仍需进一步深入研究。
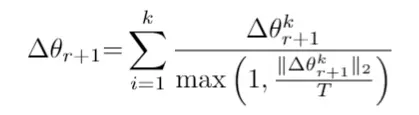
未来展望
目前的研究旨在将鲁棒性和隐私性的实验拓展到更多任务和数据集。之前的实验可能只针对特定环境或数据集。在智能交通、物联网等联邦学习的实际应用中,数据种类繁多,特性不一,急需更深入的研究,以提升联邦学习的安全性和可靠性。
关于联邦学习在将来如何平衡隐私保护与系统稳定性,你有何见解?欢迎留下你的看法,给我们点赞,并分享出去。
